mongodb training session에서 배운 내용을 요약 정리 🤓
회사에서 트레이닝을 받게 되어서 인덱스, 디자인 패턴 관련한 세션을 듣게 됐다. 2년 전 “Real MongoDB-대용량 데이터 처리를 위한” 이라는 책을 읽으며 정리했던 내용들을 다시 상기시키고, 실용적인 조언과 insight를 얻을 수 있느 좋은 기회였다.
책을 읽으며 정리한 블로그는 아래 링크에서 확인할 수 있다.
Index in MongoDB
- mongoDB 인덱스는 일반적으로 B-tree 인덱스를 사용한다.
- 인덱스 레코드는 field(인덱스 키값) + 주소 값(물리적인 위치를 가리키는 포인터)의 조합으로 이루어져 있다.
- 데이터 레코드는 기본적으로 insert 순이며 정렬되어 있지 않은 반면, 인덱스의 키값은 모두 정렬되어 있다.
인덱스의 장단점
장점
- 쿼리와 업데이트 속도를 향상시킨다.
- 필요한 range만 스캔함으로써 disk I/O를 감소시켜준다.
- 컴퓨팅 연산을 줄여준다.
- 인덱스가 있는 field 값을 검색하는 경우 이미 정렬되어 있기 때문에 빠르게 작업을 수행한다.
- 다만 인덱스의 정렬 순서와 일치하지 않는 경우에는 쿼리 옵티마이저가 메모리에서 추가 작업을 해주어야 한다.
단점
- 인덱스 추가는 모든 write에 10%의 오버 헤드를 발생시킨다.
- insert, delete : 대부분의 인덱스에 영향
- update: 업데이트될 field를 가진 인덱스만 영향
- 데이터가 커질수록 인덱스도 커지며, 인덱스가 많으면 메모리가 부족해질 수 있다
수행
- 기본적으로 쿼리를 하면 쿼리 옵티마이저가 분석 → Plan을 만듦 → Plan을 기반으로 데이터를 가져온다.
- PlanCache: 조회할 때마다 분석을 하면 비효율적이기 때문에 plan을 통해 최적의 인덱스를 찾아 캐시해놓음
- index 중 candidate index를 추림 → 1000-5000개 데이터 샘플링 → candidate index를 다 수행해봄 → 가장 score가 좋은 candidate를 캐시에 저장
- 데이터가 증가하면서 분포도가 변하면 해당 plan이 효율적이지 않을 수 있기 때문에, eviction 되기도 한다
- 특히 쿼리 옵티마이저의 통계 정보 변경 시 (데이터 변경, 인덱스 추가 및 삭제 등)
- 예) 주문 데이터를 생각해보면 초기에는 마감된 주문과 진행된 주문이 비슷할 수 있으나, 시간이 지나면서 마감된 주문이 훨씬 많아지게 됨. 이 경우 plan이 변경될 필요가 있음.
In Production
- 인덱스 빌드
- 운영 환경에서 너무 많은 데이터에 대한 인덱스 추가 또는 제거 시, rolling build 옵션을 사용한다.
- secondary → primary 순으로 인덱스 빌드하며 운영에 최소한의 영향만 끼치도록 한다.
- 히든 인덱스
- rolling build를 하더라도 인덱스 빌드는 비싼 작업이기 때문에, 삭제 작업의 경우 hidden 을 먼저 한 다음에 문제가 없을 경우 삭제하는 방식으로 진행할 수 있다.
- 쿼리 옵티마이저가 해당 인덱스를 선택하지 않도록만 하는 것이며, 삭제되는 것이 아니기 때문에 인덱스 latency는 똑같이 발생한다.
인덱스 레코드 > 데이터 조회 과정
- 쿼리 옵티마이저가 쿼리를 최적화할 수 있는 인덱스를 결정한다.
- 디스크에서 인덱스 레코드를 로드한다. (인덱스가 메모리에 매핑되어 일부 또는 전체가 캐싱되어 있어 빠름)
- 로드된 인덱스 레코드를 사용해 쿼리에 맞는 데이터를 찾는다.
- MongoDB는 데이터를 여러 페이지로 나누어 저장하고, 각 페이지는 고유한 식별자를 가지고 있다.
- 로드된 데이터 페이지에서 필요한 데이터를 읽어온다. (이러한 페이지 방식 랜덤 I/O를 줄여준다고 함)
- 최종적으로 쿼리의 결과를 반환한다.
.explain()
- 쿼리의 실행 계획을 보여줌
- excutionStats: 쿼리를 수행하고 통계도 보여줌
- 가장 많이 사용함
- queryPlanner : winning plan만 보여주고 실제 쿼리를 수행하진 않음 (몇건 가져왔는지 모름)
- execution이 너무 오래 걸릴 것으로 예상될 때 사용
- allPlansExecution: 모든 candidate plan을 보여줌 → 많이 사용하지 않음
예시 1
- 아래에서 examined = returned가 유사할 수록 효율적
- 수행 시간은 캐시 여부에 따라 달라질 수 있기 때문에, 데이터의 개수 비교가 중요하다.
- COLLSCAN은 풀 스캔이라는 뜻. 데이터가 늘어날수록 많은 자원을 사용하기 때문에 잠재적 장애 가능성
executionStats : {
executionSuccess: true,
nRetunred: 11, # 조회된 결과
executionTimeMillis: 8, # 수행 시간
totalKeysExamined 0, # 조회된 인덱스 개수
totalDocsExamined: 5555, # 조회된 도큐먼트 개수
executionStages: { # 쿼리 수행 절차
stsage: "COLLSCAN"
filter : {
...
예시2
- sort는 전 단계에서 나온 결과를 메모리에 저장해 정렬하므로 비싼 연산이다.
- 때문에 sort order는 인덱스의 order와 맞아야 한다.
executionStats : {
executionSuccess: true,
nRetunred: 2,
executionTimeMillis: 0,
totalKeysExamined 4,
totalDocsExamined: 2,
executionStages: {
stsage: "SORT"
filter : {
...
종류
많은 종류의 인덱스가 있으나, 많이 사용되는 인덱스 하나에 대해서만 정리함
compound indexes
- 하나 이상의 field로 인덱스 구성. 가장 많이 사용되며 RDBMS 인덱스와 컨셉 비슷
- order, direction 매우 중요
- 인덱스 생성한 field 순으로 인덱스 key가 정렬되기 때문
- ex.
db.people.createIndex({lastname:1, firstname:1, score:1})- 여기서 score로만 조회하면 인덱스 활용 X
- lastname / last name + first name / lastname + firstname + score 만 가능
- !! ESR !!
- Equality first
- Then Sort → Range
- 인덱스 없을 때 sort가 range 보다 훨씬 더 비싸기 때문
- 예시
- name, rating, timestamp 순으로 인덱스가 추가되어 있고, 아래 쿼리로 조회한다면 name, range 스캔된 결과가 이미 sorting 되어있기 때문에 정렬 비용이 들지 않는다.
- Query:
{timestamp: {$gte: 2, $lte:3}, username: "anonymous"} - Sort:
{rating : 1} - Index:
{username: 1, rating: 1, timestamp: 1}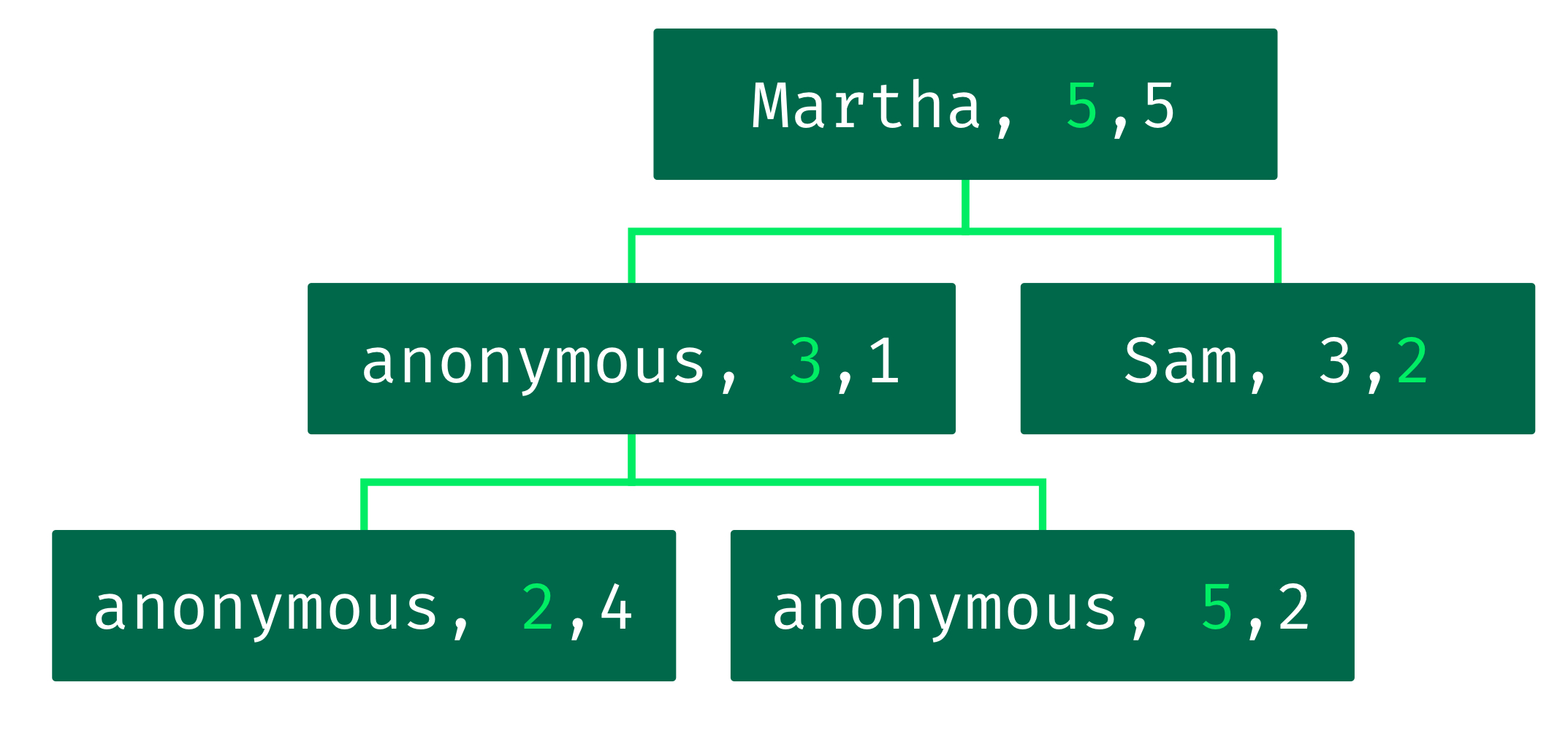
- Query:
- name, rating, timestamp 순으로 인덱스가 추가되어 있고, 아래 쿼리로 조회한다면 name, range 스캔된 결과가 이미 sorting 되어있기 때문에 정렬 비용이 들지 않는다.
Tips
- 원하는 인덱스를 타게 하고 싶다면 hint 사용
ex. db.users.find({ age : 50, … }).hint({ age : 1 })
- 정규식 match에도 인덱스 활용 가능
- collation order 사용 가능 (대소문자 구분, 발음 부호 없이 등등)
- 인덱스는 RAM based 캐시여야 함. 캐시가 아니면 디스크에서 fetch 해옴
- $indexStats aggregation을 통해 인덱스 사용량 확인 가능 (또는 아틀라스에서 조회 가능)
- 사용되지 않는 인덱스, prefix가 같은 애들은 제거해 CPU, RAM을 확보할 것
PREVIOUS프로그래머스 - 베스트 앨범