mongodb의 구조 💡
Sharding
샤딩은 여러개의 머신에서 데이터를 분산시키기 위한 방법이다. mongodb는 대량의 데이터셋에서의 배포와 운영을 지원하기 위해 샤딩을 사용한다. 데이터셋의 크기가 너무 크면 하나의 서버로는 무리가 될 수 있다. 높은 쿼리율은 서버의 CPU 가용성을 떨어트릴 수 있고, 시스템의 RAM 보다 사이즈가 더 큰 working set(주어진 시간 간격에서 프로세스에 필요한 메모리 양)은 디스크의 I/O 가용성에 무리를 줄 수 있기 때문이다. 이를 극복하기 위해 vertical, horizontal 스케일링 두 가지 방법을 사용할 수 있다.
vertical
single server의 가용성을 늘리는 방식이다. 더 파워풀한 CPU와 RAM을 추가하거나, 스토리지 용량을 증가시킨다. 다만 주어진 작업량을 처리하기에 단일 서버로는 제한적일 수 있고 하드웨어 설정에도 한계가 있기 때문에, vertical scaling에는 실질적으로 최대치가 존재할 수밖에 없다.
horizontal
시스템 데이터셋을 나누는 방법이다. 여러개의 서버를 로드하고 필요한 만큼 서버를 증가시킨다. 각 서버들의 속도나 가용성은 높지 않지만, 각각의 머신들이 전체 작업량의 부분만 관리하기 때문에 단일 서버의 high-speed, high-capacity 서버보다 더 효율성을 제공할 수 있다. 다만 인프라와 배포 유지보수에 복잡성을 더할 수 있다는 단점이 있고, mongodb는 한번 샤딩된 collection을 다시 합치는 방법을 제공하지 않는다는 점을 고려해야 한다.
Sharded Cluster
Shareded 클러스터는 아래 세 가지로 구성된다.
- shard
- 각 샤드는 데이터의 일부만(subset) 가지고 있다. 샤드는 레플리카셋으로서 배포되어야 한다.
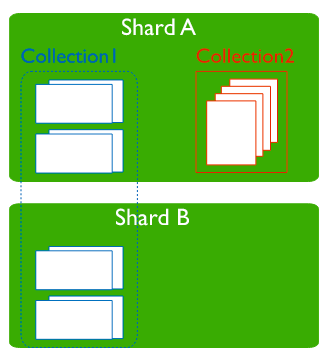
- 각 샤드는 데이터의 일부만(subset) 가지고 있다. 샤드는 레플리카셋으로서 배포되어야 한다.
- mongos
- 쿼리 라우터로서 동작한다. 클라이언트 애플리케이션과 shareded cluster 사이에 존재하는 인터페이스를 제공한다. (unsharded cluster 포함)
- sharded cluster에서 콜렉션에 적븐하기 위해서는 반드시 mongos router와 연결되어야 한다.
- config servers
- 클러스터를 위한 설정과 메타데이터를 저장한다. 레플리카셋으로서 배포되어야 한다.
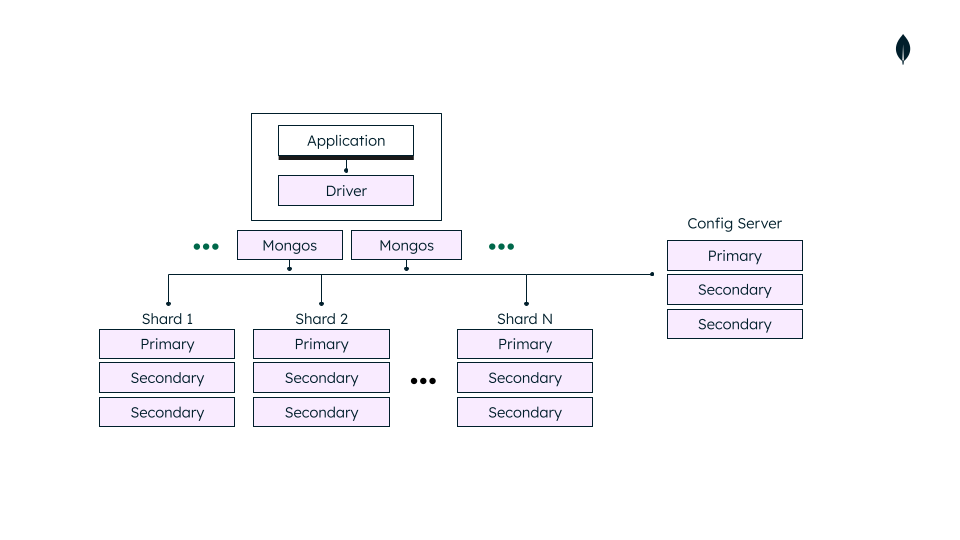
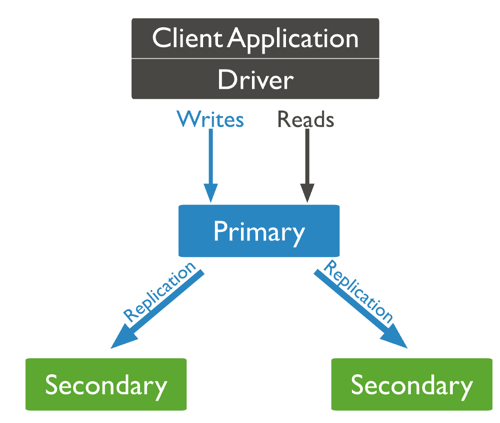
Replica Set
복제(replication)와 장애 극복 기능 (failover)을 가진 mongodb 서버들의 클러스터. 레플리카셋은 mongod 프로세스들의 그룹이고, 여분의 데이터와 고가용성을 제공하도록 구성된다. primary, secondary로 구성되며 primary가 사용 불가해졌을 때를 대비하여 레플리카셋 멤버는 3개 이상을 권장한다.
- Primary
- 레플리카 셋에서 쓰기를 받는 유일한 멤버다.
- Mongodb는 primary에 쓰기를 적용하고 primary의 oplog에 기록한다.
- Secondary는 그 로그를 복제해 그들의 데이터셋에 적용한다.
- Secondary
- Secondary는 위 로그를 복제해 primary의 카피 데이터셋을 유지한다.
둘만 남았을 때 투표가 불가하기 때문에, arbiter(투표만 하고 데이터를 저장하지 않음)를 사용할 수 있다. 레플리카셋은 50개까지 늘릴 수 있고, 그 중 투표는 7개만 참여 가능하다.
Read Concern
일관성과 고립성 (트랜잭션의 요소 중 ACID 중 C, I)을 유지시켜준다.
- local
- 대부분의 레플리카셋 멤버들에게 쓰여졌는지 보증할 수 없다. primary, secondary를 읽을 때 기본 값
- available:
- 위와 동일하나 consistent session, 트랜잭션과 함께 사용할 수는 없다.
- majority: 대다수의 레플리카셋 멤버에게 인정받은 데이터를 리턶나다.
Read Preference
Read preference는 mongodb 클라이언트가 레플리카셋 멤버 읽기 시 접근 방법을 묘사한다. 기본적으로 애플리케이션은 읽기를 할 때 레플리카 셋의 primary member를 향하지만, 클라이언트는 secondaries에 읽기를 보내도록 특정할 수 있다. 실시간으로 통계를 계산하는 쿼리(무거운 Read 쿼리)는 primary에 부하를 줄 수 있기 때문에, secondaryPreferred로 날리면 서비스가 더 안정적일 것으로 예상해, 무거운 쿼리는 secondary 옵션을 주고 있다.
- primary
- 기본 모드. 모든 읽기는 최근 레플리카셋의 primary로 가고, primary 없을 경우 에러를 냄.
- 읽기를 포함한 Multi-document transaction은 무조건 primary로 읽어야 하고, 해당 트랜잭션의 모든 수행은 같은 멤버에게 가야 한다.
- primaryPreferred
- primary가 기본이지만 불가할 경우 secondary로 가는 옵션
- maxStalenessSeconds value를 포함하면 마지막 쓰기를 통해 어떤 secondary가 가장 최신인지 확인한다.
- secondary
- 모든 읽기는 레플리카셋의 secondary로 가고, secondary가 없을 경우 에러를 낸다.
- secondaryPreferred
- 기본 secondary지만, secondary 멤버가 없을 경우 sharded cluster의 primary로 감
- nearest
- 접근할 수 있는 레플리카셋 멤버에 랜덤으로 간다.